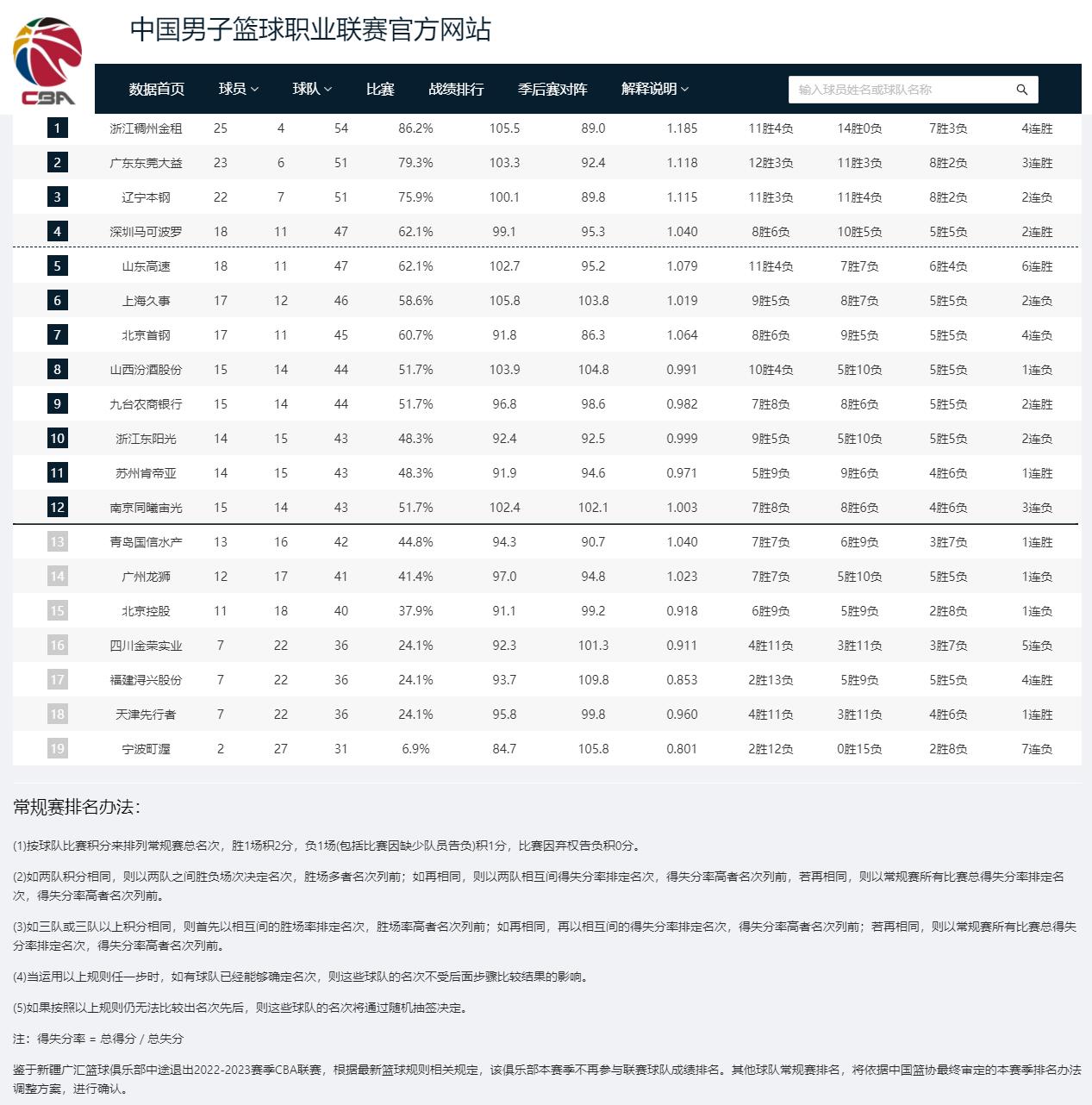
任务向量做模型编辑为何有效?ICLR 2025 Oral论文给出了理论分析
本文作者李宏康,博士毕业于美国伦斯勒理工大学,本科毕业于中国科学技术大学,并即将前往宾夕法尼亚大学担任博士后研究员。研究方向包括深度学习理论、大语言模型理论等等。本文的通讯作者为伦斯勒理工大学的汪孟教授。
任务向量(task vector)方法近来在许多视觉和语言任务中表现出了在效率与可迁移性方面的优势。但是由于人们尚未深入理解任务向量的理论机制,其在更广泛与更大规模的应用中面临挑战。
近期,一个来自美国伦斯勒理工大学、密歇根州立大学 OPTML 实验室、和 IBM 研究院的研究团队从神经网络的优化和泛化理论的角度分析了任务向量在模型编辑中的有效性。该工作已经被 ICLR 2025 录取,并被选为前 1.8% 的 Oral 论文。
论文标题:When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers论文地址:https://openreview.net/pdf?id=vRvVVb0NAz
背景介绍
任务向量(task vector)是指微调得到的模型与预训练模型之间的权重差值。人们发现,将不同的任务向量进行线性算术运算后叠加在一个预训练模型上可以直接赋予此模型多种全新的能力,例如多任务学习(multi-task learning)、机器遗忘(machine unlearning)、以及分布外泛化(out-of-domain generalization),其优势是无需使用下游任务的训练数据对模型进行微调。
这种基于任务向量的直接运算对模型进行编辑从而做下游任务预测的方法被称为任务运算(task arithmetic)。
由于缺乏对该方法的理论研究,本文重点探索任务向量方法能够被有效且高效使用的深层原因。我们的贡献如下:
我们为任务加法和减法运算的有效性提供了一个特征学习的理论分析框架。我们给出了任务运算在分布外泛化的理论保证。解释了任务向量的低秩近似和模型剪枝的理论机制。
初步观察
我们从一个简单的问题出发:组合多个任务向量的系数会受到哪些因素的影响?
直觉告诉我们,任务间的关系可能是一个关键因素。比如说,在多任务学习中,让一个模型具备两个相似任务的能力,理应是更容易的。
为了论证这一点,我们用 Colored-MNIST 数据集构建了一组二分类实验。其中,分类的标准是数字的奇偶性。我们通过调整数字的颜色来控制任务之间的关系。
于是,我们设计了「相似任务」(aligned tasks)、「无关任务」(irrelevant tasks)、「相反任务」(contradictory tasks) 的任务关系。
根据上图所示的实验结果,我们有以下观察:
在多任务学习和机器遗忘的实验中,最佳的任务运算系数会随着给定的任务向量间的关系的不同而改变。在分布外泛化的实验中,目标任务与给定任务的正反相关性可以被最佳的任务运算系数的正负性反映出来。
以上的两点发现引向了一个重要的研究方向:任务关系会如何影响任务运算。
理论分析
我们在二分类问题的设定下研究该问题。我们以一层单头的带有 softmax attention 的 Transformer 为理论分析的基本模型,用 Ψ 来表示所有权重参数的集合,其中包括 attention 层的参数 W 以及 MLP 层的参数 V。仿照许多特征学习(feature learning)的理论工作,我们做如下的数据建模:定义 μ_T 为当前任务的 discriminative pattern。数据 X 中的每一个 token 都是从 μ_T、-μ_T 以及无关的 pattern 中选择的。如果对应于 μ_T 的 token 个数多于 -μ_T 的个数,那么 X 的标签 y=1。如果对应于 -μ_T 的 token 个数多于 μ_T 的个数,那么 X 的标签 y=-1。
接下来我们给出使用两个任务向量进行多任务学习和机器遗忘的理论结果。
定理 1的结果表明:当两个任务是相似的关系的时候,将任务向量叠加可以得到理想的多任务学习性能,即泛化误差在两个任务上都达到 ϵ。
定理 2的结果表明:当两个任务是相反关系时,用 T_1 的任务向量减去 T_2 的任务向量可以得到理想的机器遗忘性能,即 T_1 的泛化误差达到ϵ,而 T_2 的泛化误差较大。
定理 3的结果表明:总是存在一组 λ_i,使得融合多个任务向量得到的模型可以在目标任务 T' 上取得理想的泛化性能。
我们还在理论上论证了对任务向量进行高效应用的方法。在我们的一层 Transformer 以及二分类问题的框架下,我们得出了推论 1:任务向量可以被低秩近似,同时只会造成很小的预测误差。这意味着人们可以将各种低秩训练和推断方法用在任务向量中,从而大大节省任务向量的计算和存储开销。
我们还可以得到推论 2:训练得到的任务向量在 MLP 层中的部分神经元权重较大,而剩余的神经元权重很小。对这些小的神经元进行剪枝只会引起很小的误差,从而使得前面所有定理依然成立。这个推论为对于任务向量进行权重剪枝与稀疏化提供了理论保障。
实验验证
我们下图的结果表明:实验中得到的能够带来出色的分布外泛化性能的 λ_1,λ_2 区域(图 A 的红色部分)与定理 3 中证明得到的(图 B 的红色部分)一致。
我们接下来用 Phi-3-small (7B) 模型对任务向量在机器遗忘中的表现进行验证,所使用的数据集为《哈利波特 I》(HP1),《哈利波特 II》(HP2),《傲慢与偏见》(PP)。其中,由于出自相同的作者 J.K. 罗琳,《哈利波特 I》与《II》的语义相似度较高,而《傲慢与偏见》与另外两个数据集不太相似。
总结
本文定量证明了如何根据任务间关系确定任务运算系数,从而实现理想的多任务学习、机器遗忘、以及分布外泛化的方法,解释了使用低秩和稀疏任务向量的可靠性。本文的理论通过实验得到了验证。
李知恩做爰猛烈叫床戏
极品人妖高潮
A級處女黃片免費看
18少妇X❌❌X❌❌OO
FerrPorno💋👙81
玖辛奈裸体被❌免费羞羞动漫
扒开❌狂揉❌脱脱内内电影91
另类videos娇小另类仙踪林
火影小南被❌吸乳视频色情
亂伦hdjapanese亂倫
18无直套
小舞婬荡高潮呻吟无码小说
3D同人动漫❌免费
精品㊙️无码一区二区三区老师
蔡徐坤被啪到深处喷水小说
哈昂拉丝漫画免费下拉式
㊙️女厕拉屎偷拍隔板
纲手被吊起来揉搓双乳小说图片
班长脱👙给我揉🐻
江楠楠脱了内裤打开腿露
水蜜桃隐私㊙️视频免费
欧美护士自慰❌❌❌○漫画
韩漫画️未删减男同
日本做受18~20岁A片
大雷擦狙官方网站入口
亚洲精品国偷拍自产在线观看蜜桃
无尽❌❌奶头❌❌裸体直播
莎莉娜催眠后被c高潮了
u蓝正太v3.0.8官网下载链接
孕妇电影大全免费国语
杨超越裸体自慰
女厕piss尿c女bbwc直播
老师好紧开裆蕾丝内裤动漫原神
小舞脱个精光露出奶头视频
斗破苍穹3d动漫同人观看网址
中国⭕⭕⭕⭕XXxX人
火影爆乳18禁🔞动漫视频
虎仗悠仁脱裤子自慰
男生凌迸了女生的里直播
把屁屁打到嫩红网站
国产人妻熟女ⅩXXX喷潮漫画
男男GayGays✅自慰网站中国
雏田被揉❌难受❌
丰满妓女BBwHD视频
寡妇的大白奶头子
老师扒开腿㊙️让我差差差
🍓导航入口㊙️国产夜月
羞羞漫画❤️在线观看43票
主人扒开女仆🍑往里面灌水作文
王乙进城一大早王乙就起来等汽车
禁止动漫🔞🔞🔞免下载观看
宇智波斑本子h十八禁
纳西妲全身棵图片
博人变成鸣人吃雏田的熊
沙特女人巨大荫蒂勃起
18禁♂自慰18cm甩啊甩
校花在体罚室被扒开腿供人玩弄
链锯人玛奇玛上衣
日本XX高清丝袜
女学生喷浆❌❌❌作文
欧美❌❌❌性丝袜老师躲避
欲梦直播露出奶头图片
揉我奶啊岳
二次元裸体无奶罩自慰白丝
露出奶头供男人用筷子夹玩
18禁露粉嫩奶头屁股视频真人
上课被学长揉花蒂喷水H
别c我⋯啊⋯嗯上课呢男男漫画
美女裸体㊙️偷拍卫生间
91♥️丨PORNY丨中文
胡桃狂揉下面❌羞羞漫画
公车嗯啊顶撞喘嗯啊H秘书视频
爆乳十八禁🔞动漫胡桃
蛋播AV无码一区二区
动漫🚫18涩涩动漫人物打屁股
芙宁娜被❌🐻黄漫
日本打白嫩㊙️屁股视频
99国产精品jk白丝AV网站
女警脱👙给我揉🐻动漫视频
国产精🦘清纯女学生
王者男英雄❌18同人禁网站免费
网友评论 查看所有评论>>